That’s the thing about mashups, almost all of them are illegal
I heard that (and unfortunately am unable to credit the source) in the “scrAPI” session at Mashup Camp, in which we discussed the delicate nature of using a site that doesn’t have APIs as part of a mashup. Adrian Holovaty of ChicagoCrime.org (my favourite mashup at camp) was leading part of the session, demonstrating what he had done with Chicago police crime data (the police, not having been informed in advance, called him for a little chat the day his site went live), Google maps, Yahoo! maps (used for geocoding after he was banned from the Google server for violating the terms of service) and the Chicago Journal.
Listening to Adrian and others talk about the ways to use third-party sites without their knowledge or permission really made me realize that most mashup developers are still like a bunch of kids playing in a sandbox, not realizing that they might be about to set their own shirts on fire. That’s not a bad thing, just a comment on the maturity of mashups in general.
The scrAPI conversation — a word, by the way, that’s a mashup between screen scraping and API — is something very near and dear to my heart, although in another incarnation: screen scraping from third-party (or even internal) applications inside the enterprise in order to create the type of application integration that I’ve been involved in for many years. In both cases, you’re dealing with a third party who probably doesn’t know that you exist, and doesn’t care to provide an API for whatever reason. In both cases, that third party may change the screens on their whim without telling you in advance. The only advantage of doing this inside the enterprise is that the third party ususally doesn’t know what you’re doing, so if you are violating your terms of service, it’s your own dirty little secret. Of course, the disadvantage of doing this inside the enterprise is that you’re dealing with CICS screens or something equally unattractive, but the principles are the same: from a landing page, invoke a query or pass a command; navigate to subsequent pages as required; and extract data from the resultant pages.
There’s some interesting ways to make all of this happen in mashups, such as using LiveHTTPHeaders to watch the traffic on the site that you want to scrape, and faking out forms by passing parameters that are not in their usual selection lists (Adrian did this with ChicagoCrime.org to pass a much larger radius to the crime stats site that its form drop-down allowed in order to pull back the entire geographic area in one shot). Like many enterprise scraping applications, site scraping applications often cache some of the data in a local database for easier access or further enrichment, aggregation, analysis or joining with other data.
In both web and enterprise cases, there’s a better solution: build a layer around the non-API-enabled site/application, and provide an API to allow multiple applications to access the underlying application’s data without each of them having to do site/screen scraping. Inside the enterprise, this is done by wrapping web services around legacy systems, although much of this is not happening as fast as it should be. In the mashup world, Thor Muller (of Ruby Red Labs) talked about the equivalent notion of scraping a site and providing a set of methods for other developers to use, such as Ontok‘s Wikipedia API.
We talked about the legality of site scraping, namely that there are no explicit rights to use the data, and the definition of fair use may or may not apply; this is what prompted the comment with which I opened this post.
In the discussion of strategic issues around site scraping, I certainly agree that site scraping indicates a demand for an API, but I’m not sure that I completely agree with the comment that site scraping forces service and data providers to build/open APIs: sure, some of them are likely just unaware that their data has any potential value to others, but there’s going to be many more who either will be horrified that their data can be reused on another site without attribution, or just don’t get that this is a new and important way to do business.
In my opinion, we’re going to have to migrate towards a model of compensating the data/service provider for access to their content, whether it’s done through site scraping or an API, in order to gain some degree of control (or at least advance notice) of changes to the site that would break the callling/scraping applications. That compensation doesn’t necessarily have to mean money changing hands, but ultimately everyone is driven by what’s in it for them, and needs to see some form of reward.
Update: Changed “scrapePI” to “scrAPI” (thanks, Thor).

 After the requisite 20 minutes of “independent content” that the vendors use to hook you into attending their webinars, Appian’s Director of Product Management, Phil Larson, stepped in and talked more about BPM in general and about their product. He was interesting enough to keep me on the line for the remainder of the webinar, and he had good illustrations of some of the concepts, including the prettiest diagram that I’ve seen to show how BPM and SOA fit together. Not the most complete, but sometimes you just need a pretty version to make your point.
After the requisite 20 minutes of “independent content” that the vendors use to hook you into attending their webinars, Appian’s Director of Product Management, Phil Larson, stepped in and talked more about BPM in general and about their product. He was interesting enough to keep me on the line for the remainder of the webinar, and he had good illustrations of some of the concepts, including the prettiest diagram that I’ve seen to show how BPM and SOA fit together. Not the most complete, but sometimes you just need a pretty version to make your point. Larson quoted from the recent Forrester report — “[Appian] has the widest breadth of functionality among the suites we evaluated” — although he didn’t mention the bit that came later in the same paragraph of the report: “However, breadth comes at the expense of depth in features like simulation and system-to-system integration“. He showed a snap of their BPMN implementation, which gets good marks off the bat for having the swimlanes running in the right direction.
Larson quoted from the recent Forrester report — “[Appian] has the widest breadth of functionality among the suites we evaluated” — although he didn’t mention the bit that came later in the same paragraph of the report: “However, breadth comes at the expense of depth in features like simulation and system-to-system integration“. He showed a snap of their BPMN implementation, which gets good marks off the bat for having the swimlanes running in the right direction.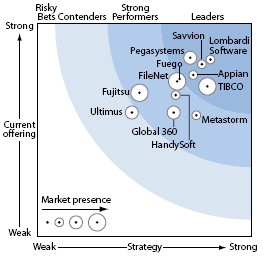
 Further to my
Further to my