I attended Alfresco’s analyst day and a customer day in New York in late March, and due to some travel and project work, just finding time to publish my notes now. Usually I do that while I’m at the conference, but part of the first day was under NDA so I needed to think about how to combine the two days of information.
 The typical Alfresco customer is still very content-centric, in spite of the robust Alfresco Process Services (formerly Activiti) offering that is part of their platform, with many of their key success stories presented at the conference were based on content implementations and migrations from ECM competitors such as Documentum. In a way, this is reminiscent of the FileNet conferences of 20 years ago, when I was talking about process but almost all of the customers were only interested in content management. What moves this into a very modern discussion, however, is the focus on Alfresco’s cloud offerings, especially on Amazon AWS.
The typical Alfresco customer is still very content-centric, in spite of the robust Alfresco Process Services (formerly Activiti) offering that is part of their platform, with many of their key success stories presented at the conference were based on content implementations and migrations from ECM competitors such as Documentum. In a way, this is reminiscent of the FileNet conferences of 20 years ago, when I was talking about process but almost all of the customers were only interested in content management. What moves this into a very modern discussion, however, is the focus on Alfresco’s cloud offerings, especially on Amazon AWS.
First, though, we had a fascinating keynote by Sangeet Paul Choudary — and received a copy of his book Platform Scale: How an emerging business model helps startups build large empires with minimum investment — on how business models are shifting to platforms, and how this is disrupting many traditional businesses. He explained how supply-side economies of scale, machine learning and network effects are allowing online platforms like Amazon to impact real-world industries such as logistics. Traditional businesses in telecom, financial services, healthcare and many other verticals are discovering that without a customer-centric platform approach rather than a product approach, they can’t compete with the newer entrants into the market that build platforms, gather customer data and make service-based partnerships through open innovation. Open business models are particularly important, and striking the right balance between an open ecosystem and maintaining control over the platform through key control points. He finished up with a digital transformation roadmap: gaining efficiencies through digitization; then using data collected in the first stage while integrating flows across the enterprise to create one view of the ecosystem; and finally externalizing and harnessing value flows in the ecosystem. This last stage, externalization, is particularly critical, since opening the wrong control points can kills you business or stifle open growth.
 This was a perfect lead-in to Chris Wiborg’s (Alfresco’s VP of product marketing) presentation on Alfresco’s partnership with Amazon and the tight integration of many AWS services into the Alfresco platform: leveraging Amazon’s open platform to build Alfresco’s platform. This partnership has given this conference in particular a strong focus on cloud content management, and we are hearing more about their digitial business platform that is made up of content, process and governance services. Wiborg started off talking about the journey from (content) digitization to digital business (process and content) to digital transformation (radically improving performance or reach), and how it’s not that easy to do this particularly with existing systems that favor on-premise monolithic approaches. A (micro-) service approach on cloud platforms changes the game, allowing you to build and modify faster, and deploy quickly on a secure elastic infrastructure. This is what Alfresco is now offering, through the combination of open source software, integration of AWS services to expand their portfolio of capabilities, and automated DevOps lifecycle.
This was a perfect lead-in to Chris Wiborg’s (Alfresco’s VP of product marketing) presentation on Alfresco’s partnership with Amazon and the tight integration of many AWS services into the Alfresco platform: leveraging Amazon’s open platform to build Alfresco’s platform. This partnership has given this conference in particular a strong focus on cloud content management, and we are hearing more about their digitial business platform that is made up of content, process and governance services. Wiborg started off talking about the journey from (content) digitization to digital business (process and content) to digital transformation (radically improving performance or reach), and how it’s not that easy to do this particularly with existing systems that favor on-premise monolithic approaches. A (micro-) service approach on cloud platforms changes the game, allowing you to build and modify faster, and deploy quickly on a secure elastic infrastructure. This is what Alfresco is now offering, through the combination of open source software, integration of AWS services to expand their portfolio of capabilities, and automated DevOps lifecycle.
This brings a focus back to process, since their digital business platform is often sold process-first to enable cross-departmental flows. In many cases, process and content are managed by different groups within large companies, and digital transformation needs to cut across both islands of functionality and islands of technology.
They are promoting the idea that differentiation is built and not bought, with the pendulum swinging back from buy toward build for the portions of your IT that contribute to your competitive differentiation. In today’s world, for many businesses, that’s more than just customer-facing systems, but digs deep into operational systems as well. In businesses that have a large digital footprint, I agree with this, but have to caution that this mindset makes it much too easy to go down the rabbit hole of building bespoke systems — or having someone build them for you — for standard, non-differentiating operations such as payroll systems.
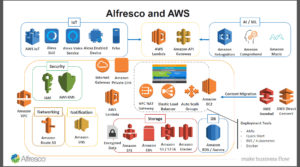
 Alfresco has gone all-in with AWS. It’s not just a matter of shoving a monolithic code base into a Docker container and running it on EC2, which how many vendors claim AWS support: Alfresco has a much more integrated microservices approach that provides the opportunity to use many different AWS services as part of an Alfresco implementation in the AWS Cloud. This allows you to build more innovative solutions faster, but also can greatly reduce your infrastructure costs by moving content repositories to the cloud.
Alfresco has gone all-in with AWS. It’s not just a matter of shoving a monolithic code base into a Docker container and running it on EC2, which how many vendors claim AWS support: Alfresco has a much more integrated microservices approach that provides the opportunity to use many different AWS services as part of an Alfresco implementation in the AWS Cloud. This allows you to build more innovative solutions faster, but also can greatly reduce your infrastructure costs by moving content repositories to the cloud.  They have split out services such as Amazon S3 (and soon Glacier) for storage services, RDS/Aurora for database services, SNS for notification, security services, networking services, IoT via Alexa, Rekognition for AI, etc. Basically, a big part of their move to microservices (and extending capabilities) is by externalizing to take advantage of Amazon-offered services. They’re also not tied to their own content services in the cloud, but can provide direct connections to other cloud content services, including Box, SharePoint and Google Drive.
They have split out services such as Amazon S3 (and soon Glacier) for storage services, RDS/Aurora for database services, SNS for notification, security services, networking services, IoT via Alexa, Rekognition for AI, etc. Basically, a big part of their move to microservices (and extending capabilities) is by externalizing to take advantage of Amazon-offered services. They’re also not tied to their own content services in the cloud, but can provide direct connections to other cloud content services, including Box, SharePoint and Google Drive.
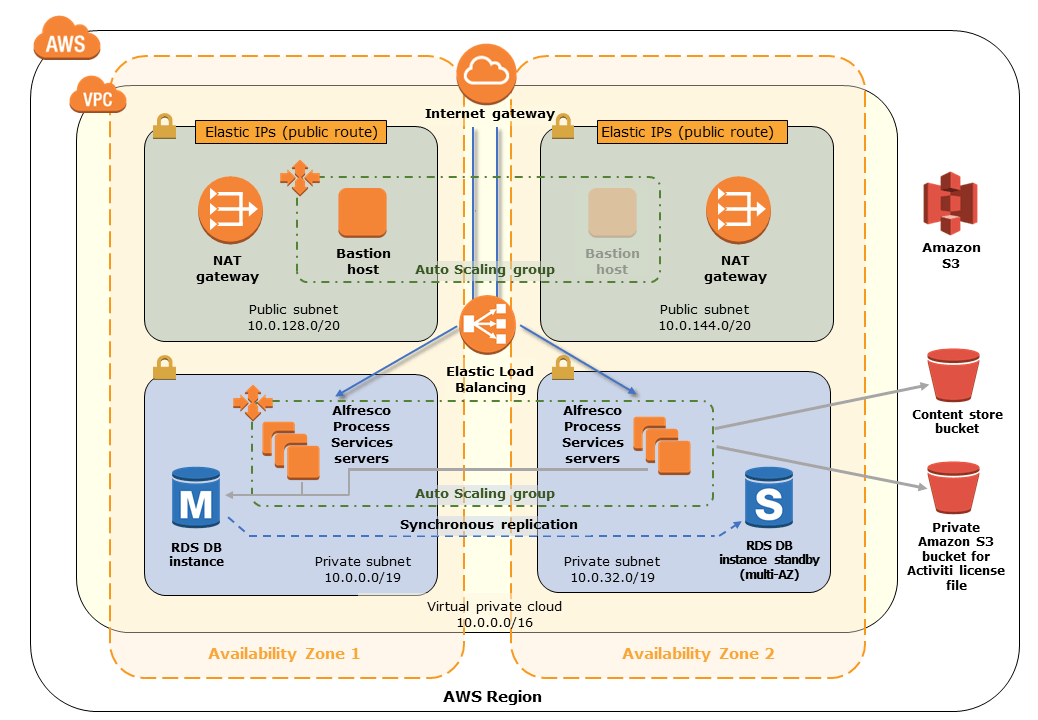
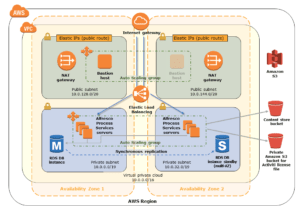 We heard from Tarik Makota, an AWS solution architect from Amazon, about how Amazon doesn’t really talk about private versus public cloud for enterprise clients. They can provide the same level of security as any managed hosting company, including private connections between their data centers and your on-premise systems. Unlike other managed hosting companies, however, Amazon is really good at near-instantaneous elasticity — both expanding and contracting — and provides a host of other services within that environment that are directly consumed by Alfresco and your applications, such as Amazon RDS for Aurora, a variety of AI services, serverless step functions. Alfresco Content Services and Process Services are both available as AWS QuickStarts, allowing for full production deployment in a highly-available, highly-redundant environment in the geographic region of your choice in about 45 minutes.
We heard from Tarik Makota, an AWS solution architect from Amazon, about how Amazon doesn’t really talk about private versus public cloud for enterprise clients. They can provide the same level of security as any managed hosting company, including private connections between their data centers and your on-premise systems. Unlike other managed hosting companies, however, Amazon is really good at near-instantaneous elasticity — both expanding and contracting — and provides a host of other services within that environment that are directly consumed by Alfresco and your applications, such as Amazon RDS for Aurora, a variety of AI services, serverless step functions. Alfresco Content Services and Process Services are both available as AWS QuickStarts, allowing for full production deployment in a highly-available, highly-redundant environment in the geographic region of your choice in about 45 minutes.
Quite a bit of food for thought over the two days, including their insights into common use cases for Alfresco and AI in content recognition and classification, and some of their development best practices for ensuring reusability across process and content applications built on a flexible modern architecture. Although Alfresco’s view of process is still quite content-centric (naturally), I’m interested to see where they take the entire digital business platform in the future.
Also great to see a month later that Bernadette Nixon, who we met at the Chief Revenue Officer at the event, has moved up to the CEO position. Congrats!




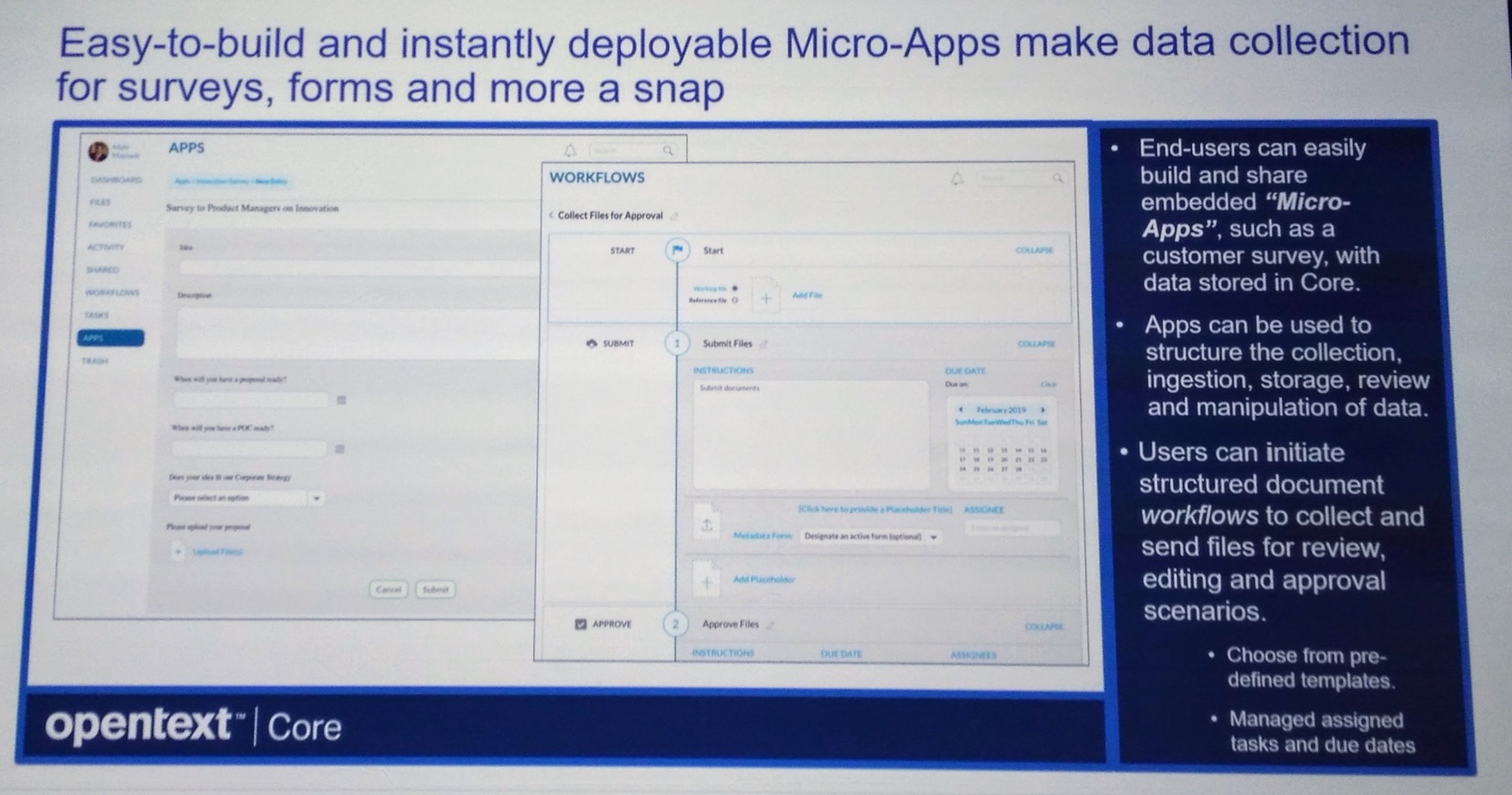
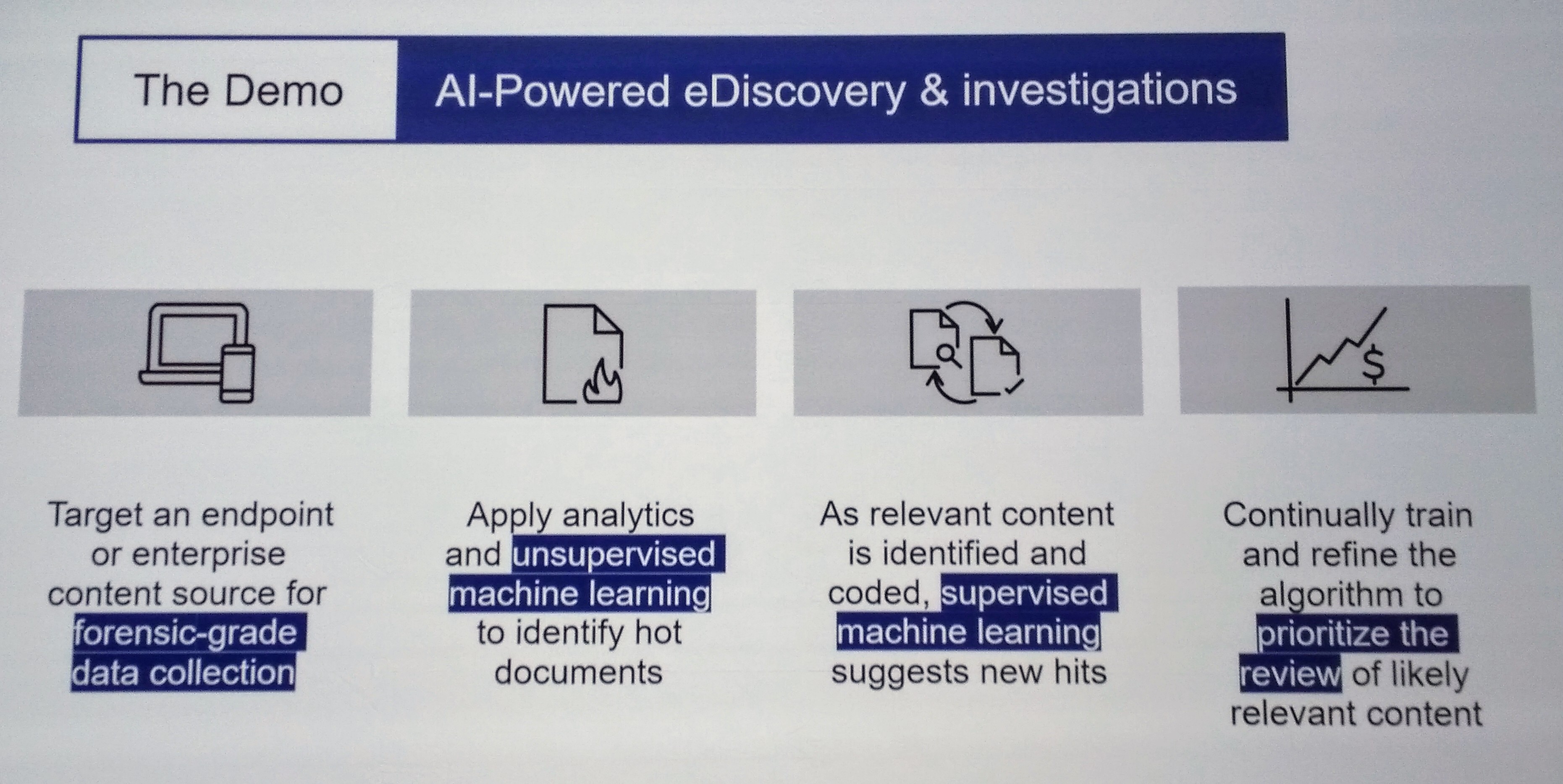



 It sounds as if most of the original work was done by a single developer, and now they have new functionality created by one student developer; on top of that, since it’s cloud-based, there’s no infrastructure cost for servers or software licences, just subscription costs for Google Apps. They keep development in-house both to reduce costs and to speed deployment. Compare the chart on the right with the cost and time for your usual content and records management project — there are no zeros missing, the original development cost was less than $50k (Canadian). That streamlined technology path has also inspired them to streamline their records management policies: now, changes to the retention schedule that used to require a year and five signatures can now be signed off by the City Clerk alone.
It sounds as if most of the original work was done by a single developer, and now they have new functionality created by one student developer; on top of that, since it’s cloud-based, there’s no infrastructure cost for servers or software licences, just subscription costs for Google Apps. They keep development in-house both to reduce costs and to speed deployment. Compare the chart on the right with the cost and time for your usual content and records management project — there are no zeros missing, the original development cost was less than $50k (Canadian). That streamlined technology path has also inspired them to streamline their records management policies: now, changes to the retention schedule that used to require a year and five signatures can now be signed off by the City Clerk alone.